
Предлагаю к прочтению интересную вещь. Интересную не только содержанием, но и формой. Это компиляция моего доклада на конференции полиграфологов, проходившей в 2025 году в Москве, с помощью ИИ. Я сам с интересом ознакомился с содержанием, испытывая странное чувство, как будто вживую наблюдаю за собой со стороны. Мысли, идеи, суть, от и до (почти от и до...кое что он всё таки придумал сам) - мои, узнаваемы и понятны, слова и предложения - это не я. Но надо отметить, что форма у ИИ получилась белее симпатичной нежели моя собственная
Здравствуйте, уважаемые читатели. Меня зовут Юрий Летков, я разработчик системы поддержки принятия решений полиграфолога (СППРП) «Сокол». Моя профессиональная жизнь сосредоточена на пересечении двух, на первый взгляд, различных вселенных: полиграфологии — прикладной дисциплины, окружённой ореолом интуиции и опыта, и строгого, формального мира математики, анализа данных и машинного обучения. Эта встреча не случайна. Я глубоко убеждён, что будущее детекции лжи лежит именно на этом перекрёстке. Сегодня я предлагаю вам погрузиться в разговор о ключевых факторах, объективно влияющих на точность заключения эксперта-полиграфолога, и наглядно продемонстрировать, почему без внедрения строгого математического аппарата полиграфология так и останется искусством, но не сможет претендовать на статус доказательной науки.
Тема нашего обсуждения — «Факторы, влияющие на точность заключения полиграфолога». Спектр таких факторов огромен: от медицинских и психофизиологических особенностей испытуемого до условий проведения проверки и квалификации самого эксперта. Однако я хочу сосредоточиться на той категории, которая часто остаётся за кадром, — на факторах математических. Такое выделение, конечно, условно, но принципиально важно. Именно эти факторы поддаются количественному измерению, объективной проверке и могут быть изучены с помощью инструментов теории вероятностей, математической статистики и анализа больших данных. Парадокс современной практики заключается в том, что на них часто не обращают должного внимания. И причина этого кроется в системном явлении, которое я называю «эффектом слабой обратной связи». Эксперт проводит тест, формирует и выдаёт заключение, но в подавляющем большинстве случаев он никогда не узнает с абсолютной достоверностью, было ли его заключение верным. Не существует налаженного механизма, который бы сообщал полиграфологу: «Тот проверочный случай, по которому вы три месяца назад вынесли вердикт „лжёт“, в итоге был подтверждён неопровержимыми уликами». В условиях отсутствия такой «обратной связи» закономерно снижается и мотивация к скрупулёзному анализу внутренней точности собственных методик. Зачем совершенствовать то, эффективность чего невозможно проверить? Однако если мы всерьёз говорим о доказательности, этот барьер необходимо преодолеть, начав с фундамента — с математического осмысления процесса.
Часть 1. Кризис доверия: одна таблица на все случаи жизни
Давайте проанализируем типичный рабочий процесс современного эксперта. После проведения теста (например, методики «Юта») полиграфолог анализирует записанные физиологические реакции, присваивая им некие числовые оценки — баллы. Эти баллы, полученные по разным каналам (дыхание, КГР, АД, ФПГ), суммируются, и на выходе формируется некий интегральный показатель, скажем, -6 или +3. Что дальше? Далее эксперт обращается к священному Граалю — стандартной таблице соответствия баллов и вероятности достоверности. Подобные таблицы кочуют из одного учебного пособия в другое, их можно найти в интернете и в программном обеспечении полиграфов. Алгоритм кажется безупречным: получил суммарный балл -6, нашёл его в таблице, прочитал, что ему соответствует вероятность достоверности 97,7%, аккуратно вписал эту цифру в заключение. Работа сделана, моральный и профессиональный долг выполнен.
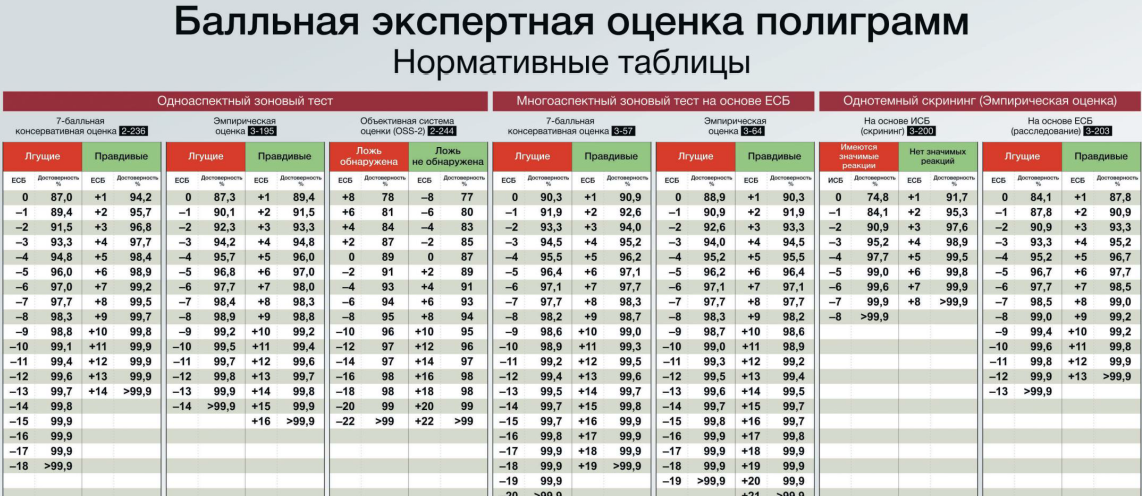
Однако давайте зададимся простыми, но решающими вопросами. Для каких конкретно методик составлена эта таблица? Применима ли она одинаково к «Юте» с тремя повторами и к «Юте» с пятью повторами? Сколько «живых» (не отмеченных как артефактные) проверочных вопросов было в тесте, на основе которого таблица построена? Какие именно физиологические каналы использовались при её создании: стандартный набор из дыхания (Д), кожно-гальванической реакции (КГР) и манжеты (АД), или, может быть, фото-плетизмограмма (ФПГ) вместо манжеты? Ответа в таблице нет. Она претендует на универсальность, но в этом и заключается её главная методологическая ошибка.
Рассмотрим гипотетическую, но абсолютно реалистичную ситуацию. Эксперт №1 проводит тест «Юта» в три повтора. В его протоколе, допустим, 9 проверочных вопросов, из которых один помечен как артефакт. После анализа он получает интегральный балл -6. Эксперт №2 проводит тест «Юта» в пять повторов. В его протоколе 15 проверочных вопросов, все «живые». В силу специфики случая он также получает балл -6. Оба смотрят в одну и ту же таблицу и оба с чистой совестью указывают в заключении вероятность достоверности 97,7%. Но с точки зрения математики и логики — это абсурд! Потому что балл — это не просто число, это реализация случайной величины. А случайная величина определяется не только своим единичным значением, но и законом распределения, дисперсией, математическим ожиданием и другими параметрами. Эти параметры кардинально зависят от условий «эксперимента»: от объёма данных (количества повторов и вопросов), от состава каналов, от доли артефактов. Следовательно, и вероятность, вычисленная для одного и того же числового значения балла, но полученного в радикально разных условиях, должна быть разной. Использование единой универсальной таблицы — это не упрощение, это профанация, основанная на незнании или игнорировании базовых принципов теории вероятностей.
Этот тезис легко проиллюстрировать на примере программного обеспечения современных компьютерных полиграфов. Я провёл ряд простых, но показательных экспериментов. Взяв реальную полиграмму, я вручную выставил нулевые значения в каналах дыхания и плетизмограммы (фактически, симулировав их отсутствие или полное отсутствие реакции), оставив «работающими» только КГР и АД. Суммарный балл, рассчитанный программой, составил, к примеру, -2. Программа, сверившись со своим внутренним «справочником», присвоила этому результату вероятность достоверности 92,3%. Затем я полностью исключил каналы дыхания и ФПГ из алгоритма расчёта, оставив для анализа только КГР и АД. Суммарный балл, что логично, остался -2. И что же? Программа снова выдала вероятность 92,3%!
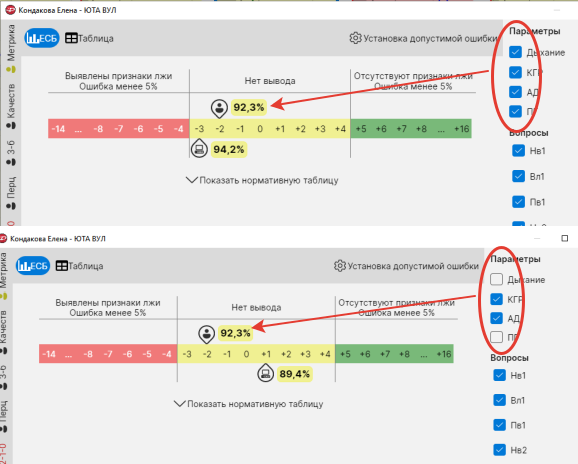
С математической точки зрения это невозможно. Исключив два канала из анализа, я фундаментально изменил саму случайную величину — «интегральный балл». Изменилось её распределение, дисперсия, все её параметры. Вероятность получения конкретного значения этой новой величины при условии истинности той или иной гипотезы (человек лжёт / говорит правду) должна быть пересчитана заново. Но программа, как и эксперт с таблицей, работает по принципу «одинаковое число на входе — одинаковый результат на выходе», что является грубейшей ошибкой.
Аналогичный эксперимент можно провести и с количеством вопросов. Допустим, в исходном тесте было 12 «живых» проверочных вопросов. Я вношу изменения: снимаю отметки «артефакт» с трёх ранее забракованных вопросов, но вручную выставляю на них нулевые баллы (то есть формально они снова в игре, но их вклад в сумму — ноль). Общий суммарный балл при этом не изменится. Однако объём статистических данных, которые мы анализируем, увеличился с 12 до 15 элементов. Изменилась ли точность оценки? Безусловно. Должна ли измениться итоговая вероятность достоверности? Непременно. Но и таблица, и стандартное ПО этого «не заметят». Корректный алгоритм обязан учитывать всю метаинформацию о тесте: количество повторов, количество «живых» вопросов, количество и тип исключённых артефактов, набор используемых физиологических каналов. Без этого любая декларируемая «вероятность» лишена научного смысла.
Часть 2. Фактор №1: Объём данных — основа статистической мощности
Таким образом, первый и фундаментальный математический фактор — это учёт объёма данных. Интуитивно каждый понимает: чем больше информации, тем точнее вывод. Если мы зададим испытуемому проверочный вопрос всего один раз, наша оценка будет крайне ненадёжной. Если мы повторим этот вопрос в рамках методики пять раз и получим повторяющуюся реакцию, наша уверенность возрастёт. Но как перевести эти интуитивные представления в конкретные цифры? Как количественно оценить, насколько возрастает точность при переходе от трёх повторов к пяти?
Для ответа на этот вопрос необходимы обширные эмпирические данные. Благодаря содействию многих коллег-полиграфологов, несколько лет присылавших анонимизированные полиграммы с известными, верифицированными исходами, у нас сформировалась обширная база данных. Однако перед нами встала серьёзная методологическая проблема. Наша выборка была чрезвычайно разнородной: разные методики («Юта», другие зоновые тесты, их модификации), разное количество повторов (2, 3 до 5 и более), разное количество «живых» проверочных вопросов, разные комбинации каналов. Выделить из этого массива однородные группы для чистого сравнения (например, «только „Юта“, 3 повтора, 9 вопросов, каналы Д+КГР+АД») оказалось почти невозможно — в каждой такой «ячейке» было слишком мало полиграмм для статистически значимых выводов.
Здесь на помощь приходит мощный статистический метод — бутстреп (bootstrap). Попробую объяснить его суть без сложных формул. Представьте, что у вас есть 10 уникальных пирожков, испечённых по особому рецепту. Больше ингредиентов нет. Классическая статистика скажет: ваша выборка ограничена 10 единицами. Бутстреп предлагает иной подход. Мы можем мысленно «клонировать» эти пирожки, создавая из исходной десятки виртуальные наборы по 100, 1000 или 10 000 «пирожков», сохраняя при этом вероятностные свойства оригинала. Это не магия, а основанная на теории вероятностей процедура случайного выбора с возвращением. Именно этот метод позволил нам преодолеть ограниченность исходной выборки полиграмм.
Мы применили процедуру бутстрепа, чтобы сгенерировать большие однородные наборы данных для разных сценариев и оценить, как точность зависит от числа проверочных вопросов (что эквивалентно увеличению повторов). Результаты были впечатляющими и наглядными. Мы оценивали, в частности, долю неопределённых результатов, когда алгоритм отказывается выносить однозначное решение из-за недостатка данных:
При 3 проверочных вопросах неопределённость составляла около 57%. То есть более чем в половине случаев система говорила: «Данных слишком мало для вывода».
При 6 вопросах — уже 29%.
При 9 вопросах — 15%.
При 15 вопросах — всего 5%.
Прогностические ценности — положительная (ППЦ, вероятность того, что положительное заключение верно) и отрицательная (ОПЦ, вероятность верности отрицательного заключения) — при этом также росли. Однако здесь критически важно сделать одно уточнение. В реальной жизни заказчик ждёт не статистического отчёта, а чёткого ответа: «лжёт» или «не лжёт». Если мы исключим категорию «неопределённости» и посмотрим на точность только тех заключений, которые были бы вынесены как определённые, картина станет ещё более поучительной:
При 3 проверочных вопросах точность (ППЦ/ОПЦ) падает до уровня около 85%. Это значит, что каждое шестое или седьмое определённое заключение, выданное в таких условиях, с высокой вероятностью будет ошибочным.
По мере увеличения количества вопросов до 9-12 точность устойчиво растёт, приближаясь к 98-99%.
Из этого следует простой, но суровый практический вывод: малое число повторов/вопросов ведёт к неприемлемо высокому риску ошибки. Однако здесь кроется важнейшее предостережение. Полученные нами цифры справедливы только при условии единообразия процедуры тестирования. А теперь давайте посмотрим на распространённую практику. Многие эксперты поступают «гибко»: проводят три повтора теста, и если физиологические реакции «хорошие», «чистые», то на этом останавливаются и выносят решение. Если же реакции «плохие», «смазанные», они добавляют ещё два повтора, чтобы «разобраться». С точки зрения математики это катастрофа. Вы таким образом создаёте две принципиально разные выборки: в одной (3 повтора) — только «хорошие» случаи, в другой (5 повторов) — только «сложные». Статистические закономерности, выведенные для одной выборки, полностью неприменимы к другой. Если эксперт хочет оперировать объективными вероятностями, он обязан выбрать единый, неизменный протокол (например, ВСЕГДА 5 повторов) и неукоснительно его соблюдать. Только тогда можно говорить о научной обоснованности его выводов.
Часть 3. Фактор №2: Информативность каналов — не все датчики созданы равными
Второй ключевой фактор, игнорирование которого обесценивает традиционный балльный подход, — это разная диагностическая ценность (информативность) физиологических каналов. В существующей практике баллы, полученные с датчиков КГР, АД, дыхания и ФПГ, часто просто суммируются, как если бы они были равнозначными монетами одного достоинства. Но что, если одна из этих «монет» — золотая, другая — серебряная, а третья и четвёртая — медные? Их номинальная сумма будет вводить в заблуждение.
Ещё до активного внедрения машинного обучения визуальный анализ тысяч полиграмм подсказывал нам иерархию: наиболее отзывчивым и информативным каналом выглядела кожно-гальваническая реакция (КГР). За ней следовала манжета (АД, измерение кровяного давления). Дыхание (Дых) и фото-плетизмограмма (ФПГ, измерение кровенаполнения в кончике пальца) занимали места в конце списка. Но интуиции и визуальной оценки недостаточно. Нам нужны были точные, количественные меры.
Для этого мы обратились к алгоритму машинного обучения «Случайный лес» (Random Forest). Одним из его замечательных свойств является способность в процессе обучения рассчитывать важность признаков (feature importance). В нашем контексте признаками являются параметры, извлечённые из сигналов разных физиологических каналов. Алгоритм, анализируя, какие признаки чаще и точнее всего позволяют разделить полиграммы на классы «ложь» / «правда», присваивает каждому каналу числовой вес информативности. Результаты (на нашей обучающей выборке) оказались следующими:
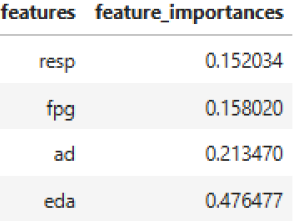
Кожно-гальваническая реакция (КГР): ~48% информативности. Абсолютный и безоговорочный лидер, несущий половину всей полезной диагностической информации.
Манжета / Артериальное давление (АД): ~21%. Стабильный «серебряный призёр».
Дыхание (Д) и Фотоплетизмограмма (ФПГ): делят оставшиеся примерно 31%, причём их вклад часто бывает сопоставимым и существенно меньшим, чем у лидеров.
Важно отметить, что конкретные проценты могут незначительно колебаться в зависимости от состава обучающей выборки, но порядок и пропасть между лидерами и аутсайдерами остаются неизменными: КГР>> АД> Д ≈ ФПГ.
Каковы практические последствия этого факта? Рассмотрим два гипотетических эксперта. Эксперт А использует в работе три канала: Дыхание, КГР и Манжету (Д+КГР+АД). Наша оценка показывает, что прогностическая ценность его тестов (ППЦ/ОПЦ) может достигать 94%/92%. Эксперт Б по каким-то причинам (личное предпочтение, нелюбовь к манжете) решает работать с другим набором: Дыхание, КГР и Фотоплетизмограмма (Д+КГР+ФПГ). Фактически, он заменил высокоинформативный канал АД (21%) на низко информативный ФПГ. В результате прогностическая ценность его заключений резко падает, по нашим оценкам, до уровня 85%/82%.
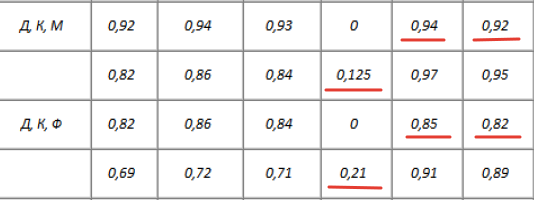
Это не мелкая погрешность, это существенная потеря точности, которая может быть критической в реальном расследовании. Ирония в том, что в текущей парадигме оба эксперта, получив, скажем, суммарный балл -6, посмотрят в одну таблицу и укажут одинаковую вероятность 97,7%. Различия в информативности используемого инструментария полностью нивелируются упрощённой методикой. Это уже не просто упрощение — это профанация, приводящая к реальным, но скрытым ошибкам.
Часть 4. Фактор №3: Нелинейность, ансамбли и мудрость толпы
Традиционный метод баллов по своей сути линеен. Мы берём числа (баллы) и складываем их. Но физиология человека, а тем более её связь с когнитивными и эмоциональными процессами, — система глубоко нелинейная. Свести её к линейной модели — значит отказаться от огромного пласта информации. Современная математика и наука о данных предлагают инструменты для работы с этой сложностью.
В разработанной нами системе «Сокол» используется не один, а несколько алгоритмов классификации, включая тот же «Случайный лес» и другие модели. Их работу координирует специальный мета алгоритм, или метаоценщик. Его можно представить как опытного арбитра или председателя учёного совета. Он не анализирует сырые данные полиграммы, а изучает «мнения» всех нижестоящих алгоритмов. И здесь иногда возникают удивительные, с точки зрения линейной логики, ситуации.
Представьте: пять базовых алгоритмов, проанализировав полиграмму, выдают результаты на грани чувствительности, в сторону обвинения. Их «уверенность» низка, значения вероятностей находятся около порога принятия решения, условно «51-55%». Каждый по отдельности не готов вынести однозначный вердикт. А метаоценщик, обобщив эту картину, выдаёт итог: «Нет решения», но при этом подсвечивает его зелёным цветом, что в нашей системе означает мета-указание на склонность к варианту «невиновен»/«говорит правду». При проверке по базе полиграмм с известными исходами выясняется, что в подавляющем большинстве таких случаев метаоценщик был прав.

В чём же секрет? Метаоценщик (реализованный, например, в виде нейронной сети или алгоритма градиентного бустинга) обучался на обширном массиве данных. В процессе обучения он «увидел» тысячи различных конфигураций реакций. Он «запомнил», что именно такая специфическая, слабая, но при этом согласованная картина «сомнений» всех алгоритмов очень часто ассоциируется с правдивыми ответами. Его логика — нелинейна. Он оперирует не суммой баллов, а сложными, многомерными паттернами, улавливая скрытые корреляции и зависимости, которые недоступны примитивной линейной арифметике. Это не ошибка или глюк, это более высокий уровень анализа, который можно сравнить с врачебной интуицией, основанной на тысячах увиденных случаев, но формализованной в алгоритме.
Это подводит нас к ещё одному мощному математическому принципу, лежащему в основе современных алгоритмов, — теореме Кондорсе о жюри присяжных. В упрощённом виде она утверждает: если каждый член группы независимых «судей» принимает правильное решение с вероятностью хотя бы чуть больше 50%, то коллективное решение, принятое по принципу большинства голосов, при увеличении числа судей стремится к абсолютной правильности. Классическая народная мудрость «Одна голова хорошо, а две — лучше» получила строгое математическое доказательство.
Алгоритм «Случайный лес» — прямое воплощение этой теоремы. Он строит не одно «дерево решений» (простой классификатор), а сотни или тысячи.
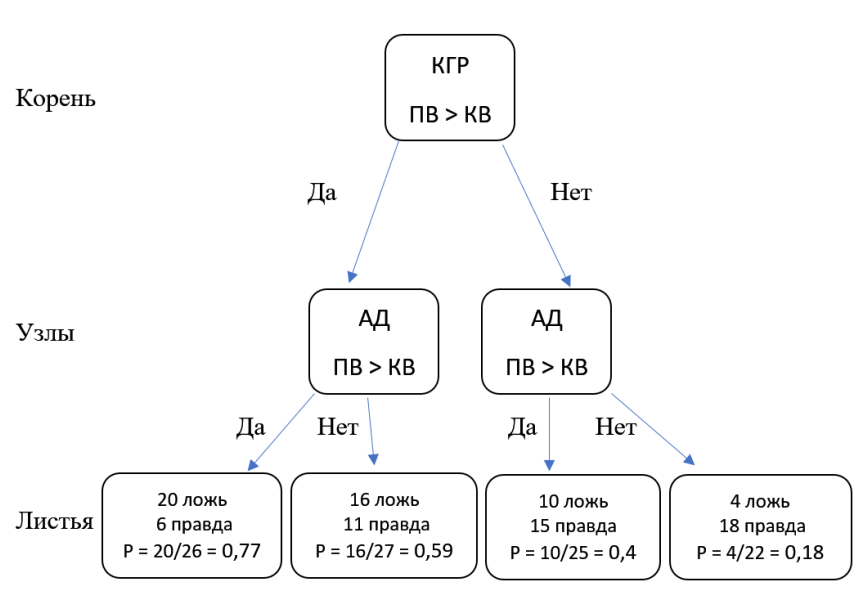
Каждое дерево — как отдельный, не слишком умный «присяжный», который ошибается довольно часто. Но когда все эти тысячи «присяжных» независимо голосуют, их коллективное решение оказывается поразительно точным. Именно поэтому в СППРП «Сокол» заложен принцип ансамбля алгоритмов. По той же причине мы используем несколько физиологических каналов: каждый канал — это независимый «свидетель», чьё «показание» (данные) голосует в составе алгоритмического «жюри». Чем больше независимых и информативных «свидетелей», тем точнее итоговый вердикт.
Часть 5. Практические ориентиры: согласованность и путь вперёд
Помимо описанных строгих факторов, существует и эмпирически наблюдаемый показатель, полезный для практикующего эксперта — согласованность реакций по разным каналам. Если на проверочный вопрос наблюдается выраженная, синхронная реакция одновременно на КГР, АД и в паттерне дыхания — это сильный сигнал. Наша выборочная проверка примерно на 100 тестах показала: в случаях полной межканальной согласованности (все каналы «голосуют» в одну сторону) процент ошибочных решений был крайне низок — менее 4%. Когда же каналы «спорят» друг с другом (один указывает на значимость, другой — на незначимость), неопределённость и риск ошибки возрастают. Эксперт может использовать это наблюдение как дополнительный критерий внутреннего контроля: высокая согласованность — аргумент в пользу большей уверенности в выносимом заключении, конфликт каналов — повод для предельной осторожности и, возможно, дополнительных проверок.
Заключение: от ремесленной интуиции к инженерной точности
Полиграфология сегодня стоит перед судьбоносным выбором. Она может остаться ремеслом, основанным на субъективном опыте, условных таблицах и неверифицируемых методах, постоянно находясь под огнём критики со стороны научного сообщества. Либо она может сделать сложный, но необходимый шаг к становлению в качестве доказательной дисциплины. Для этого требуется фундаментальный пересмотр подходов:
Отказ от догматичных таблиц. Вероятность достоверности должна вычисляться динамически, в реальном времени, с учётом ВСЕХ параметров конкретного тестирования: применённой методики, количества фактических повторов, числа «живых» проверочных вопросов, конкретного набора используемых каналов и их известной информативности.
Взвешенный учёт каналов. Необходимо внедрять математические модели, которые при формировании итогового вывода присваивают разный вес данным от КГР, АД, дыхания и ФПГ, отражая их реальную диагностическую ценность.
Стандартизация и единообразие. Ключевое условие любой статистики — повторяемость условий. Протокол тестирования должен быть строго фиксированным и неизменным для сравнимых категорий дел. «Гибкость» в количестве повторов губит любую возможность объективной оценки точности.
Принятие нелинейности. Необходимо активно разрабатывать и внедрять современные алгоритмы машинного обучения (ансамбли, нейронные сети), способные выявлять сложные, нелинейные паттерны в данных, повышая точность сверх возможностей линейных методов.
Математика как основа. Основы, хотя бы на уровне средней школы, теории вероятностей, математической статистика и анализ данных должны перейти в категорию обязательных профессиональных компетенций полиграфолога, претендующего на звание эксперта.
Только так мы сможем перейти от категоричных, но зачастую бездоказательных вердиктов к научно обоснованным заключениям, сопровождаемым объективной, просчитанной оценкой их достоверности. Только так полиграфология сможет сбросить с себя ярлык «лженауки» и занять достойное место в ряду инструментов современной криминалистики и кадрового менеджмента. Математика — это не сухой язык формул, а самый надёжный и честный союзник в поисках истины. Пора этим союзником воспользоваться в полной мере. Будущее полиграфологии — не за гаданием, а за расчётом.
